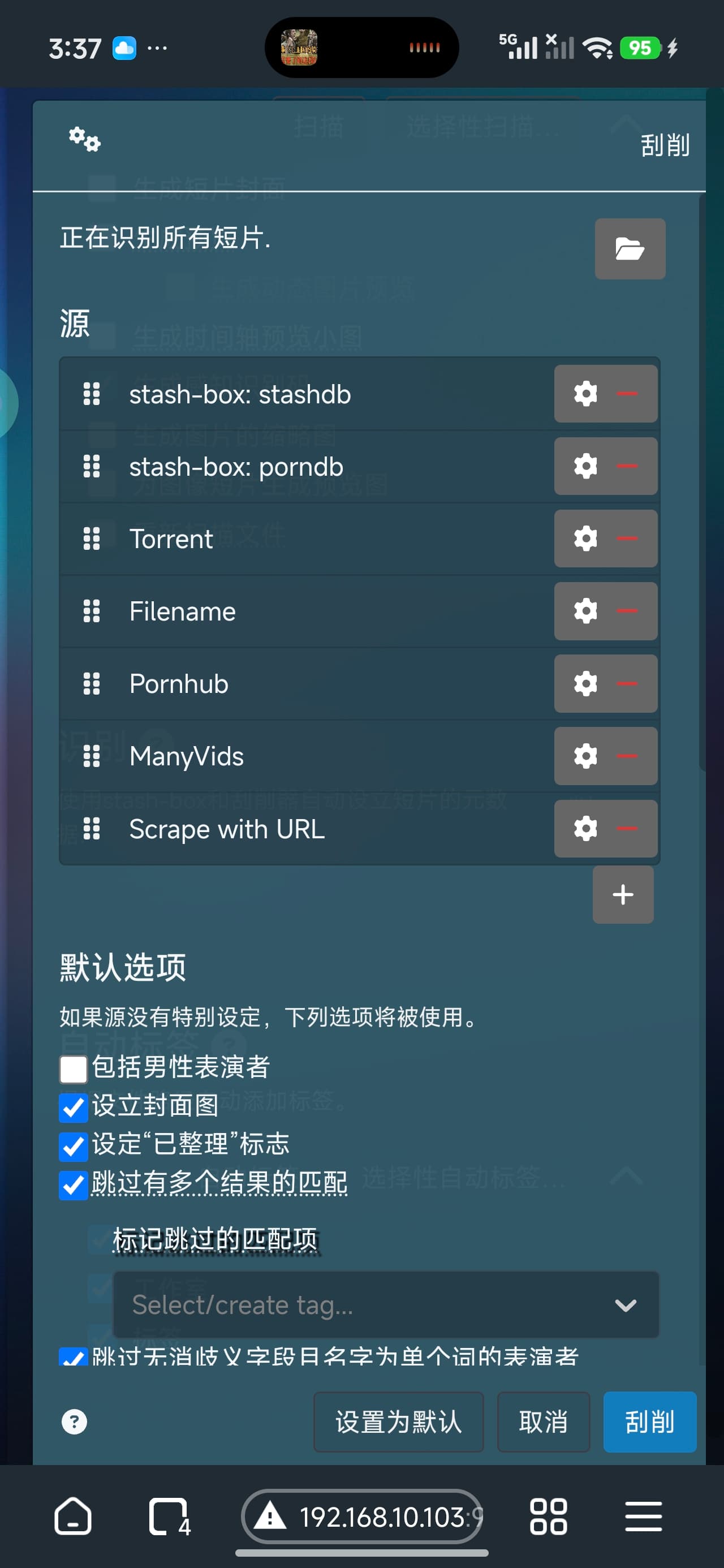
I want to know some strange scrapers. How they work
Torrent
Scrape with URL
Filename
What homework do they have?
I want to know some strange scrapers. How they work
Torrent
Scrape with URL
Filename
What homework do they have?
I understand this much. Using URLs for scraping I need to scan the code beforehand, manually and quickly fill in the URL information, and then the scraper runs. That shouldn’t be the case, because you can manually scrape after filling in the URL. So, this is the correct usage. Now, regarding torrents. Assuming a 200GB file contains images and videos, what will be read from it, and how is it different from a direct download?
If I recall correctly, Torrent scarper scans .torrent files for embeded metadata, which not all trackers do. Parsed metadata: title, image, details, tags, performers, date, url.