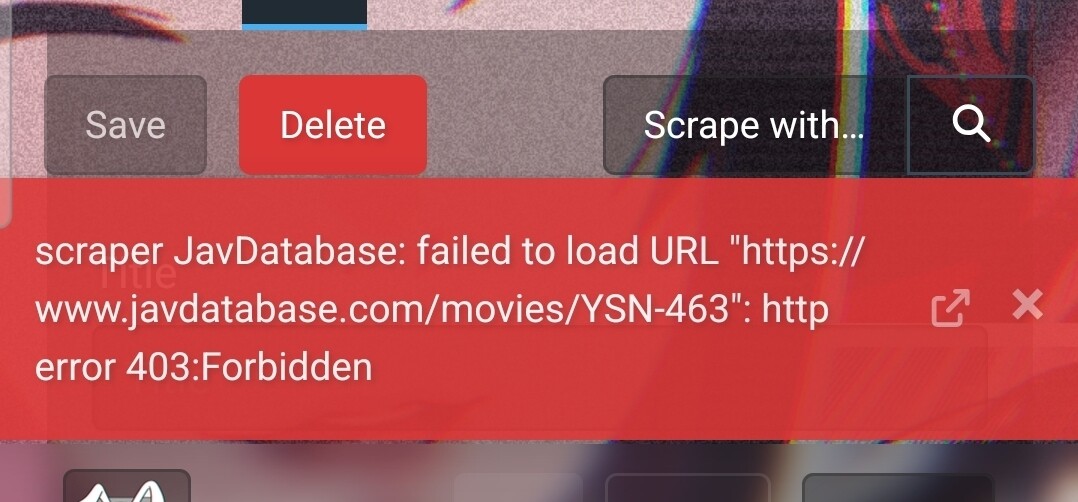
I just spent 16 hours reading crawling throug various pages , dicussions trying everything. The only scraper that work is the StashDB and JAVstash(which to my understanding is more like a metadata warehouse) of which is not ideal becasue StashDB have so few JAV title and mix between ENG and JAP. The other is only Japanese language. I tried every built-in community scraper and none of them work either they return error like “dial tcp: lookup www.javlibrary.com: no such host”. then I tried install the skScraper which I don’t know how exactly it work, There is no new scraper option.
I’am at my wit’s end here.
Ther very least I want is just a cover image and title name in english.
I think the architecture as it stands for scraping metadata through existing implemented methods on stash has ran its course and probably needs to be revisited. You are at the mercy of the web host or cloud providers security which is a big no no.
People can suggest stashdb, but I have no interest in using that feature. For users like us, there needs to be a more modular solution. I have got around this in the past by using local scripts and passing the browser session key. Perhaps i(or somebody anyway) could make the ground work for a modular plugin to pass this key in to scrape sites. This should bypass cloudflare.
To be honest though I havent really sat down and thought on it for a long time. This is merely an idea ive thought about in the last hour, but the problem is certainly real and its definitely time to rethink a solution.
You can also scrape directly from R18.dev who offer dumps of their metadata at https://r18.dev/dumps. You can then use local Stash scraper from JAV Stash admin to scrape against it.
More so that no user-input required scrapers are becoming more rare. Another thing we can thank LLMs for. Before anti-scraper measures were an afterthought as hobbiest scrapers weren’t a threat. Not that multiple bots powered by LLMs mass scrape the whole internet on a daily basis, it can’t be an afterthought as no protection can lead to them effectively DDoSing you and in some cases leading to expensive bills.
Yeah im well aware of the cause but we need a solution. Ai and scrapers aren’t going anywhere anytime soon. In some light reading we might be able to use playwright as a plugin. But its all guess work for me for now.
Nice to see its on your radar but Im assuming this is mostly with automation in mind? While I know thats the goal for anything these days, I dont think people wouldnt mind a manual option as long as the clicks are minimal. Like I mentioned before passing a session key or browser session to impersonate could be a decent workaround.
browser sessions/ session keys are ephemeral (on the scale of 30mins-1h) so yes, complete automation is preferred.
TLS impersonation should be quite light and fast (negligible memory/ binary increase) compared to the 300MB of disk for chromedriver/byparr and 500MB-1G of memory usage